Back to Projects
AI Platform
RAG
Overview
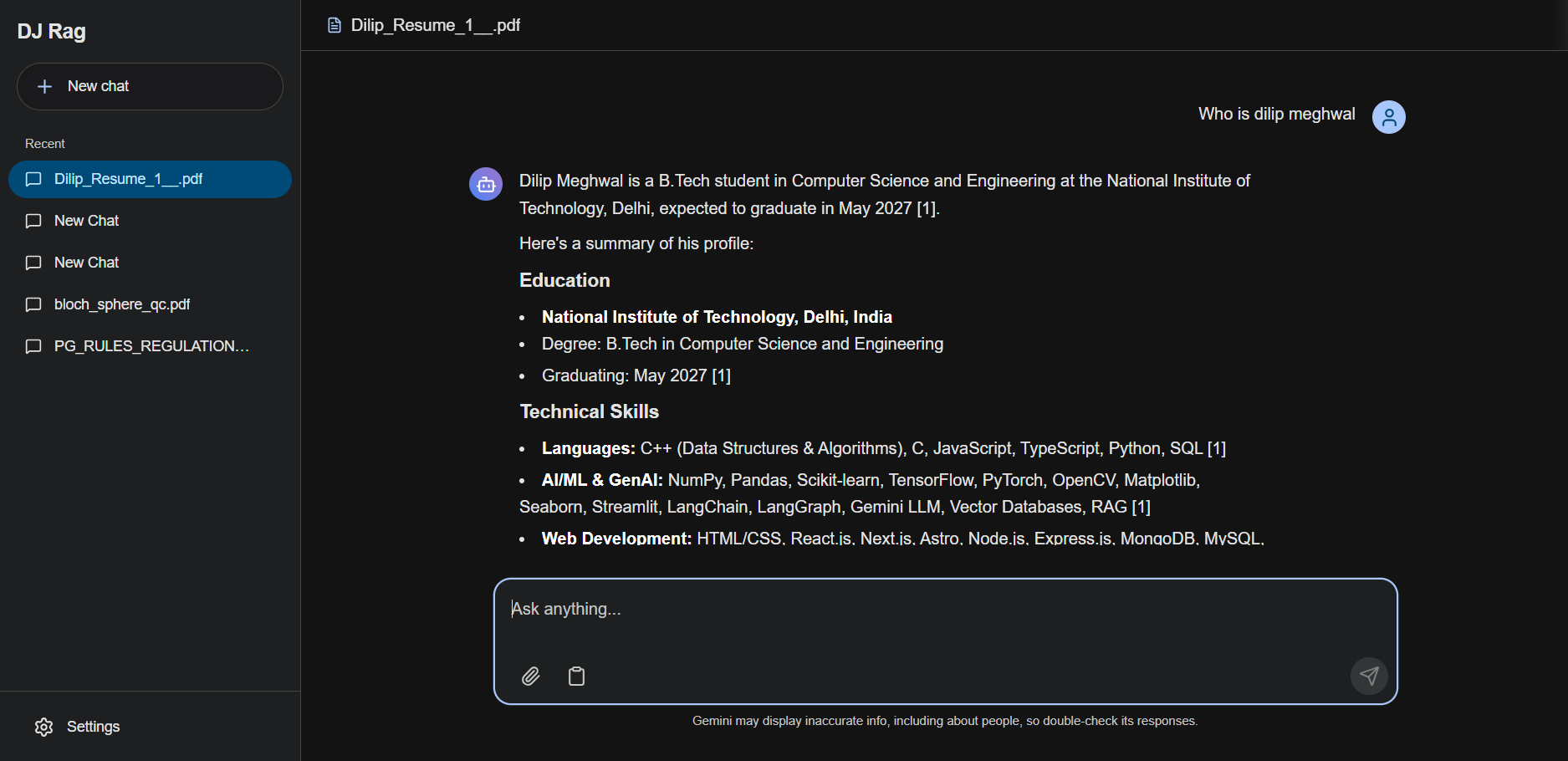
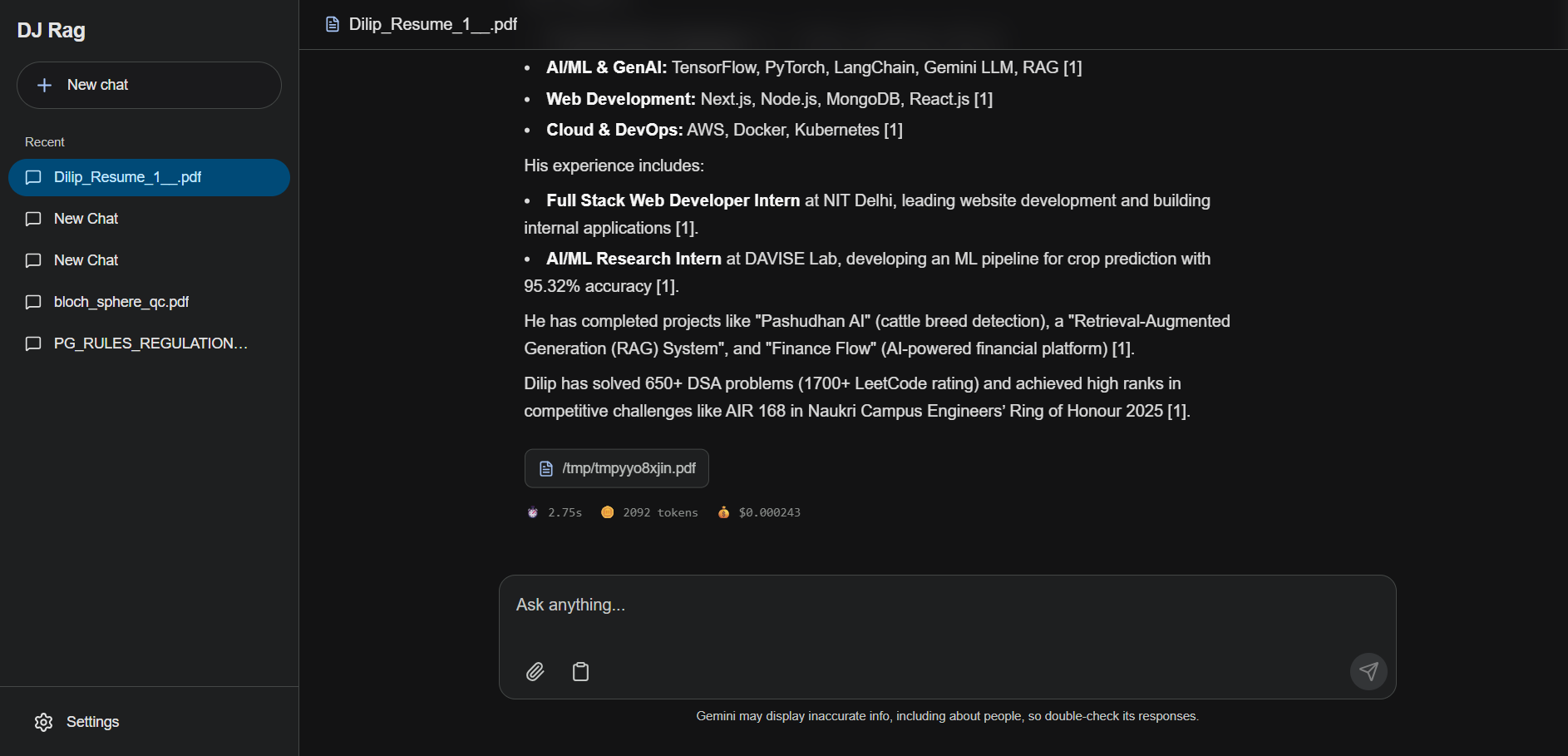
RAG is a modern, production-grade Retrieval-Augmented Generation application built to deliver highly accurate Q&A across multiple document formats. The architecture separates a sleek Next.js 16 client from a robust FastAPI backend that orchestrates document ingestion, vector searches, and LLM reasoning. By coupling semantic retrieval with local post-retrieval reranking, the system optimizes context window usage and enhances answer precision.
- Multi-Format Chunking & Indexing: Extracts structured text from PDF, DOCX, PPTX, Excel, CSV, and TXT uploads, applying LangChain's RecursiveCharacterTextSplitter with a 4,000-character chunk size and 400-character overlap before indexing into Pinecone.
- Semantic Search & Reranking: Leverages Pinecone's inference API using the 1024-dimensional llama-text-embed-v2 model to perform similarity search, followed by FlashRank cross-encoder reranking to distill retrieved documents into the top five most relevant chunks.
- Contextual Query Rephrasing: Translates conversational history into standalone search queries using a pre-generation prompt with Gemini 2.5 Flash, generating responses with precise markdown formatting and inline document source citations.
- Session-Isolated Storage: Manages persistent chat logs and session metadata using an SQLAlchemy-managed SQLite database, implementing session-based metadata filters in Pinecone to target queries and clear vector indices during session deletion.
Technologies
Next.jsFastAPIPythonGoogle GeminiPineconeLangChain
FL
FlashRankSQLiteSQLAlchemyTailwind CSSFramer MotionProject Glimpse